Build Cursor Tab in less than 300 lines of lua
Code completion in Cursor has long fascinated me since it's just so stupid quick. How exactly is it able to figure out what I need so quickly? Well, the short answer is it just runs a small model locally. If that's the case, building our own should be straightforward. Let's create a Neovim plugin that does exactly that!
We'll utilize a small model for understanding our code and then completing it. In our case, we'll use Qwen 2.5 Coder 1.5b. I'm on a mac pro using an M4 chip with 16GB of memory. Plenty of horsepower for this model, but your results may vary.
Get the model up and running
Download ollama. I just went to their website and hit the download button.
Download the model from the terminal
❯ ollama pull qwen2.5-coder:1.5b
- Run the model
❯ ollama run qwen2.5-coder:1.5b
>>> Send a message (/? for help)
Model capabilities
Nice! Got the model running. I made a simple prompt asking the model to act as a code completion agent that knows how to logically complete C++ snippets. Let's see what the model's capabilities are.
>>> int main() {
Sure! Heres an example of how I might complete a `main` function based on your input:
'''cpp
#include <iostream>
int main() {
// Your code goes here
return 0;
}
'''
>>> a = 1; b = 3; if(a >
Sure! Here's an example of how I might complete the `if` statement based on your input:
'''cpp
#include <iostream>
int main() {
int a = 1;
int b = 3;
if(a > b) {
std::cout << "a is greater than b" << std::endl;
} else {
std::cout << "b is greater than or equal to a" << std::endl;
}
return 0;
}
'''
Pretty impressive. I can put in some simple enough code snippets and it knows exactly what to do. But! Most importantly, it does it very fast. That's a big requirement for this one.
Modelfile
Ollama gives us the ability to create a Modelfile which will allow us to create an agent for our purposes. Here's what mine looks like.
FROM qwen2.5-coder:1.5b
# set the temperature to 1 [higher is more creative, lower is more coherent]
PARAMETER temperature 0.3
PARAMETER top_p 0.3
# set the system message
SYSTEM """
You are a code completion expert. When a code snippet is given to you, it's your
job to complete the snippet in the most logical way possible. Your responses
should be the code only. You'll be provided with the language and then the code you
need to complete.
Example:
``'
LANGUAGE: <language>
CODE: <code snippet>
``'
"""
Create this file and then create a custom model via the cli:
❯ ollama create tab -f Modelfile
Now we have a model called tab that's specifically tuned for code completion.
Building a nvim plugin
I used this post for getting started with building the plugin. My preferred method was to setup the plugin using Lazy:
require("lazy").setup({
-- tab plugin
{
dir = vim.fn.expand("~/dev/tab"),
name = "tab",
lazy = false,
config = function()
require("tab").setup()
end,
},
-- ... other plugins
})
The plugin structure is pretty straightforward. We'll have two main files:
lua/tab/
├── init.lua # Main plugin logic
└── ollama.lua # API communication
Let's start with the Ollama API wrapper since that's the foundation everything else builds on.
-- ollama.lua
Making async requests
The key to making this feel fast is ensuring our HTTP requests don't block the UI. Neovim's jobstart function is perfect for this! It lets us run shell commands asynchronously.
Here's our ollama.lua file:
local M = {}
local function interp(s, tab)
return (s:gsub('($%b{})', function(w) return tab[w:sub(3, -2)] or w end))
end
-- Escape JSON string for shell command
local function escape_json(str)
return str:gsub('\\', '\\\\'):gsub("'", "'\\''")
end
function M.make_request_async(lang, snippet, callback)
-- Escape the snippet for JSON
local escaped_snippet = escape_json(snippet)
local escaped_lang = escape_json(lang)
-- Build the curl command
local json_data = string.format(
'{"model": "tab", "prompt": "LANGAUGE: %s CODE: %s", "stream": false}',
escaped_lang,
escaped_snippet
)
-- Use jobstart for async execution
local stdout_data = {}
local job_id = vim.fn.jobstart(
{"curl", "-s", "http://localhost:11434/api/generate", "-d", json_data},
{
stdout_buffered = true,
on_stdout = function(_, data)
if data then
for _, line in ipairs(data) do
if line and line ~= "" then
table.insert(stdout_data, line)
end
end
end
end,
on_exit = function(_, exit_code)
if exit_code == 0 and #stdout_data > 0 then
local raw_output = table.concat(stdout_data, "\n")
local ok, parsed = pcall(vim.json.decode, raw_output)
if ok and parsed and parsed.response then
callback(parsed.response)
else
callback(nil)
end
else
callback(nil)
end
end,
}
)
-- Return job_id so it can be cancelled if needed
return job_id > 0 and job_id or nil
end
return M
The important parts here:
jobstart- Runs curl in the background without blockingon_stdout- Collects the response as it comes inon_exit- Parses the JSON and calls our callback with the completion- Return value - The job ID lets us cancel requests if the user keeps typing
This is the async foundation. Now let's build the UI on top of it.
-- init.lua
Displaying suggestions with virtual text
Neovim's extmarks API lets us display text that doesn't actually exist in the buffer. Perfect for showing completions! We'll use virt_text for inline suggestions and virt_lines for multi-line completions.
The core display logic looks like this:
local function show_suggestion(bnr, line, col, suggestion_text, current_line_content)
-- Clean the suggestion (remove markdown code blocks)
local cleaned_text = clean_suggestion_text(suggestion_text)
-- Remove already-typed portion for display
local display_text = cleaned_text
if current_line_content and current_line_content ~= "" then
if cleaned_text:sub(1, #current_line_content) == current_line_content then
display_text = cleaned_text:sub(#current_line_content + 1)
end
end
-- Split into lines
local suggestion_lines = vim.split(display_text, "\n")
if #suggestion_lines > 0 then
local first_line = suggestion_lines[1]
local remaining_lines = {}
for i = 2, #suggestion_lines do
table.insert(remaining_lines, {{suggestion_lines[i], "Comment"}})
end
-- Show first line inline, rest below
local opts = {
id = 1,
virt_text = {{first_line, "Comment"}},
hl_mode = "blend",
}
if #remaining_lines > 0 then
opts.virt_lines = remaining_lines
end
api.nvim_buf_set_extmark(bnr, ns_id, line, col, opts)
end
end
The clever bit here is stripping what you've already typed. If you type local var and the model suggests local var = 'value', we only show = 'value' as the virtual text. Much cleaner!
Debouncing requests
We don't want to hammer the API on every keystroke. A simple debounce timer does the trick:
local debounce_timer = nil
local function debounced_autocomplete()
-- Clear existing timer
if debounce_timer then
debounce_timer:stop()
debounce_timer = nil
end
-- Clear current suggestion immediately when typing
local bnr = api.nvim_get_current_buf()
clear_suggestion(bnr)
-- Set new timer for 200ms
debounce_timer = vim.defer_fn(function()
request_autocomplete()
debounce_timer = nil
end, 200)
end
Every time you type, we reset the 200ms timer. Only after you stop typing for 200ms do we actually make the API call. This keeps things snappy without overwhelming the model.
Wiring it all together
Now we need to hook into Neovim's text change events and set up Tab completion:
function M.setup()
-- Trigger on text changes in insert mode
api.nvim_create_autocmd("TextChangedI", {
group = augroup,
callback = function()
debounced_autocomplete()
end,
})
-- Clear suggestions when leaving insert mode
api.nvim_create_autocmd("InsertLeave", {
group = augroup,
callback = function()
clear_suggestion(api.nvim_get_current_buf())
-- Cancel any pending requests
end,
})
-- Tab completion
vim.keymap.set("i", "<Tab>", function()
local suggestion = current_suggestions[api.nvim_get_current_buf()]
if suggestion then
-- Replace entire line with suggestion
local suggestion_lines = vim.split(suggestion.text, "\n")
local keys = "<C-o>cc" -- Change entire line
for i, line in ipairs(suggestion_lines) do
if i > 1 then
keys = keys .. "<CR>"
end
keys = keys .. line:gsub("<", "<lt>")
end
return vim.api.nvim_replace_termcodes(keys, true, false, true)
end
return "<Tab>" -- Fall back to default
end, { expr = true })
end
The Tab completion uses <C-o>cc which switches to normal mode, deletes the entire line, and enters insert mode. Then we insert all the suggestion lines. A little hacky but effective!
The complete picture
Here's the flow:
- You type in insert mode
TextChangedIfires → debounce timer starts- After 200ms of no typing → API request goes out (async, doesn't block)
- Response comes back → virtual text appears showing the continuation
- Press Tab → entire line gets replaced with the full suggestion
All of this happens without freezing your editor. The async requests mean you can keep typing while completions are being fetched.
Putting it all together
The full init.lua is about 250 lines. The key pieces are:
- State management - Track suggestions per buffer, manage timers
- Async requests - Use
jobstartto avoid blocking - Virtual text - Display suggestions without modifying the buffer
- Debouncing - Don't spam the API
- Tab completion - Replace line with suggestion on Tab
You can see the complete code in the repository. The beauty is in the simplicity! No complex state machines or elaborate parsing. Just async requests, virtual text, and a debounce timer.
Demo!
Here's what it looks like in action:
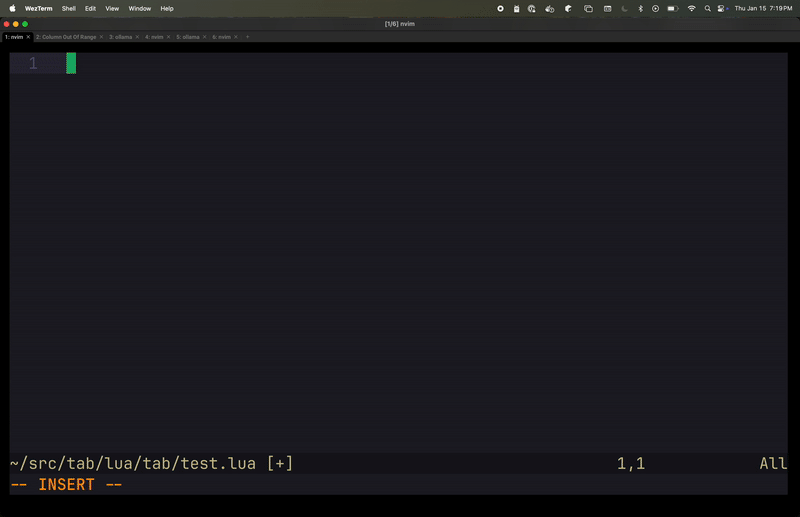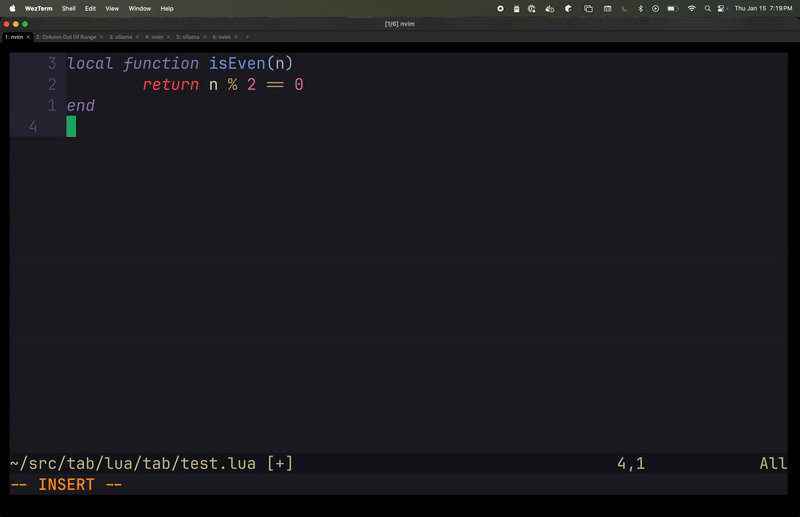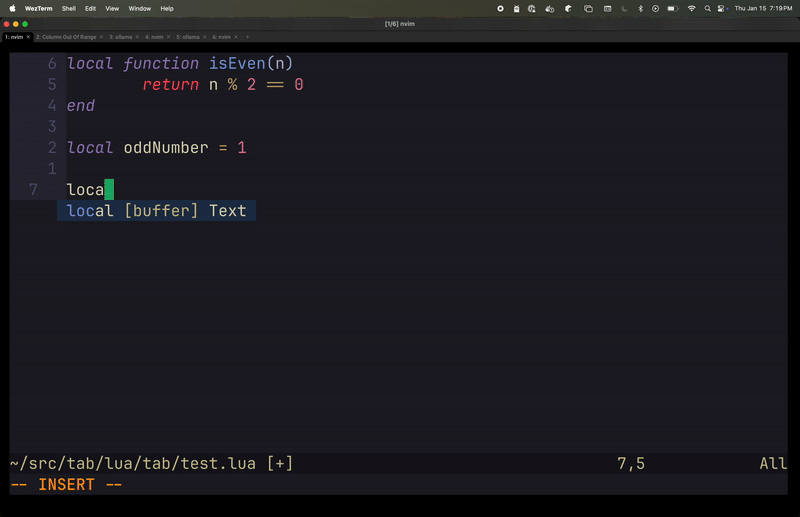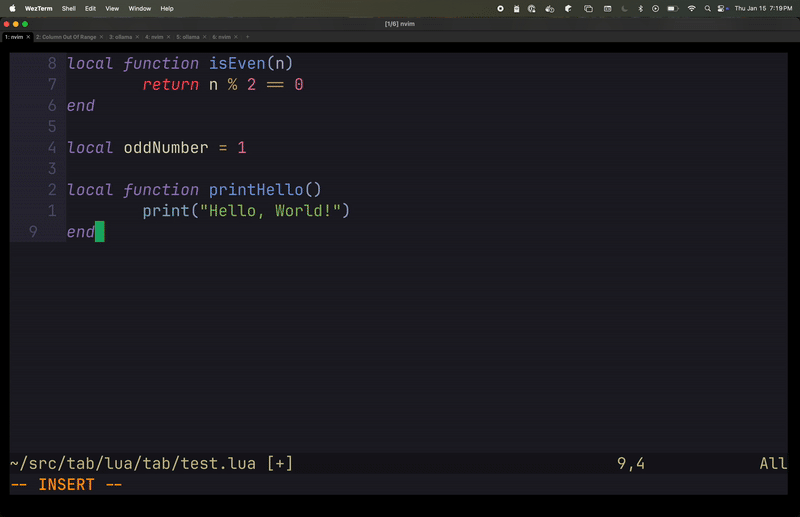
What's next?
This is a solid proof of concept, but there's plenty of room for improvement:
- Context awareness- Send more surrounding code for better completions
- Multiple suggestions - Show a few options and let users cycle through
- Language-specific tuning - Different prompts for different file types
- Caching - Remember completions for similar code patterns
The foundation is there though. With less than 300 lines of Lua, we've got a working code completion plugin that feels fast and doesn't get in your way. Not bad!